本文是近期阅读 NeRF + SLAM 相关论文的精读笔记。
1、iNeRF: Inverting Neural Radiance Fields for Pose Estimation
摘要翻译
我们提出了 iNeRF,这是一个通过反转一个神经辐射场(NeRF)来执行无网格位姿估计的框架。NeRF 已经被证实在新视图合成任务重令人震撼的效果——合成真实场景或物体的逼真新颖的新视图。在这项工作中,我们研究了我们是否可以通过 NeRF 将合成分析应用于无网格,仅有 RGB 的 6自由度位姿估计——给定图像,找到相机相对于三维物体或场景的平移和旋转。我们的方法假设在训练和测试期间是没有可用的物体网格模型的。从初始位姿估计开始,我们使用梯度下降法去最小化从 NeRF 中渲染的像素和观察图像中的像素之间的残差。我们首先研究1)如何在 iNeRF的位姿优化过程中采样射线以收集梯度信息;2)不同批量大小的射线如何影响在合成数据集上的 iNeRF。随后,我们展示了对于 LLFF 数据集的复杂真实世界下,iNeRF 可以通过估计新视图的相机姿态将这些图像用作 NeRF 的额外训练数据集来改进 NeRF。最后,我们展示了 iNeRF 可以通过反转从单个视图推断的 NeRF模型,对 RGB 图像执行类别级的对象姿态估计,包括训练期间未看到的物体实例。
方法介绍
- Overview
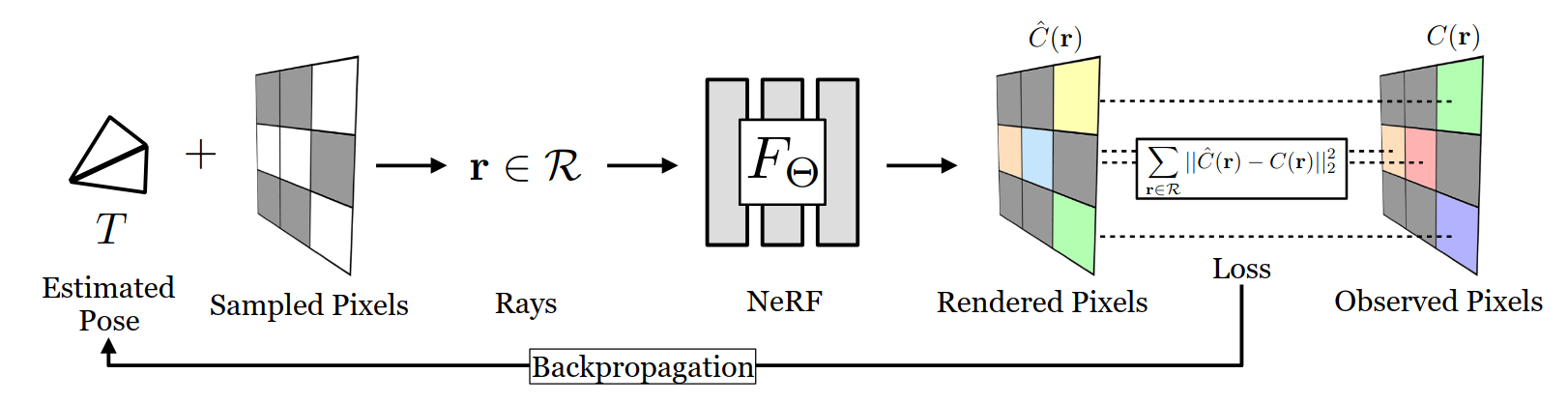
- 问题定义
是否可以通过 NeRF 将合成分析应用于无网格,仅有 RGB 的 6自由度位姿估计——给定图像,找到相机相对于三维物体或场景的平移和旋转。
- Gradient-Based SE(3) Optimization
在 SE(3) 上进行流形优化,其优化对象为相机位姿:
将上述优化问题转化为李代数的形式进行求解:
最终的梯度求解问题为:
- Sampling Rays
对全图的所有像素点进行采样的话,其计算量过大,同时也容易采样到无效的区域,所以作者提出了不同的射线采样策略来解决这个问题。
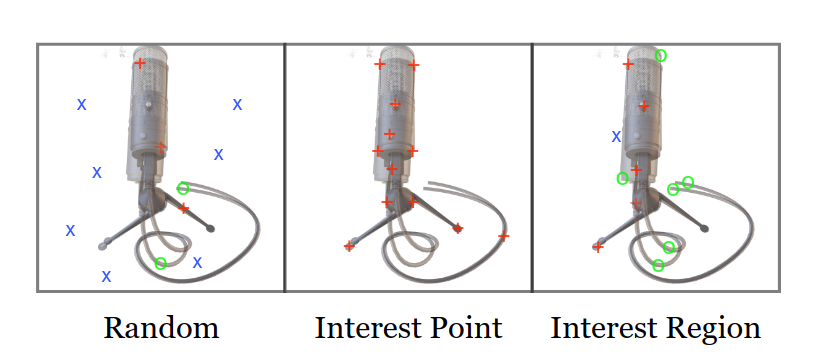
先后采用了三种采样测量:
- 随机采样:无效点偏多;
- 感兴趣点采样:采用关键点搜索的方法查询关键点,关键点不够时再进行部分随机采样来达到采样点数。
- 感兴趣区域采样:防止兴趣点采样进入局部最小值,将兴趣点为中心进行扩张掩模。
- Self-Supervising NeRF with iNeRF
用 iNeRF 对 NeRF 进行自监督训练:
- 通过一组已知位姿和对应图像得到 NeRF 的参数;
- 通过 iNeRF 对未知位姿的图像进行位姿优化得到位姿;
- 将上一步得到的图片与对应的位姿打上标签送到 NeRF 的训练网络中。
2、BARF : Bundle-Adjusting Neural Radiance Fields
摘要翻译
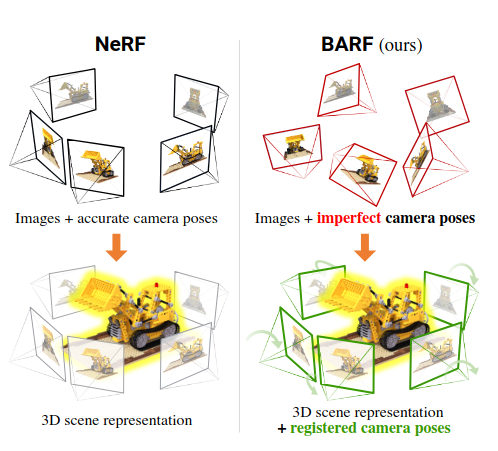
神经辐射场(NeRF)最近在计算机视觉界已经引起了人们极大的兴趣,因为它有着强大的合成真实世界场景的逼真的新颖视图的能力。然而,NeRF的一个局限性在于它需要精确的相机位姿来学习场景表示。在本文中,我们提出了束调整神经辐射场(BARF)来用于从不完美(甚至不知道)的相机位姿中训练NeRF——学习神经三维表示和配准相机帧的联合问题。我们建立了与经典图像对齐理论的联系,并标明从粗糙到精细配准也使用于NeRF。此外,我们也表明,在NeRF中错误地使用位置编码对基于合成的物体的配准具有负面影响。在合成和真实数据上的实验表明,BARF可以有效地优化神经场景表示,同时解决大型相机位姿偏移问题。这使得能够对来自位置相机姿势的视频序列进行视图合成和定位,为视觉定位系统(即SLAM)和稠密三维建图和重建开辟了全新的道路。
方法介绍
- 问题定义
我们提出了束调整神经辐射场(BARF)来用于从不完美(甚至不知道)的相机位姿中训练NeRF——学习神经三维表示和配准相机帧的联合问题。
- Overview
- Neural Radiance Fields (3D)
图像渲染方程,即原 NeRF 中的渲染方程:
联合位姿信息后的渲染方程表示:
最终图像优化函数:
根据二维图像配准推断出来的优化梯度为:
- On Positional Encoding and Registration
为了高效完成反向传播,需要对位置信息进行编码,从而得到光滑的信号,防止进入局部最优。
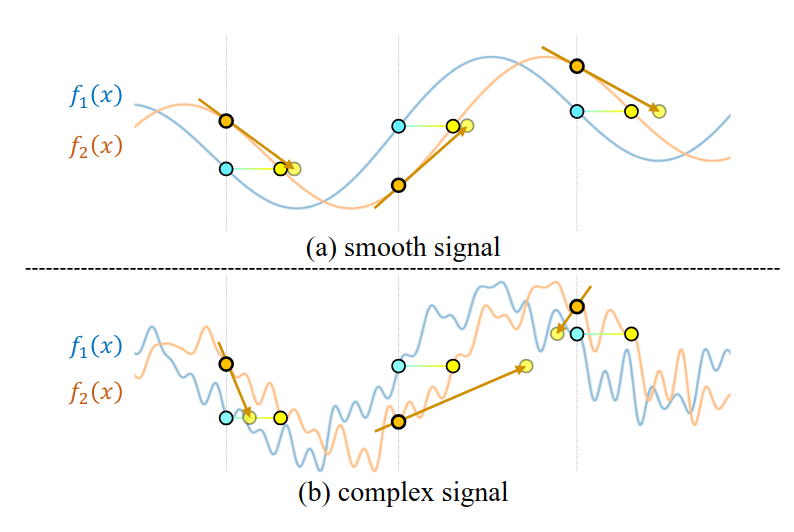
编码公式:
编码优化梯度:
- Bundle-Adjusting Neural Radiance Fields
关键思想是在优化过程中,在不同频带(从低到高)的编码上应用平滑掩码,这就像动态低通滤波器一样。修改后的编码公式为:
编码优化梯度:
3、iMAP: Implicit Mapping and Positioning in Real-Time
摘要翻译
我们首次展示了多层感知器(MLP)可以作为手持RGB-D相机的实时SLAM系统中的唯一场景表示。我们的网络在没有事先数据的情况下进行实时操作训练,构建了一个密集的、特定场景的占用和颜色隐含3D模型,该模型也可立即用于跟踪。
通过针对实时图像流对神经网络进行持续训练来实现实时SLAM需要重大创新。我们的iMAP算法使用关键帧结构和多处理计算流程,动态信息引导像素采样以提高速度,跟踪频率为10Hz,全局地图更新频率为2Hz。隐式MLP相对于标准密集SLAM技术的优势包括具有自动细节控制的有效几何表示,以及对未观察到的区域(如物体的背面)的平滑、合理的填充。
方法介绍
- 问题定义
在没有事先数据的情况下对网络进行实时操作训练,构建了一个密集的、特定场景的占用和颜色隐含3D模型,该模型也可立即用于跟踪。
- Pipeline
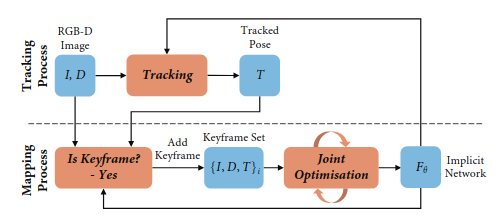
- Implicit Scene Neural Network
区别于 NeRF ,本文采用 Gaussian positional encoding 进行编码。
- Depth and Colour Rendering
采用经典体渲染公式得到深度和光度信息:
同时,计算深度协方差信息:
- Joint optimisation
光度损失采用 L1 范数损失,通过深度协方差对不确定的边缘部分进行优化:
得到最终的优化损失函数:
相机追踪: 运行一个并行跟踪线程,在使用相同的损失和优化器的同时,以比联合优化高得多的帧速率持续优化最新帧相对于固定场景网络的姿态。
- Keyframe Selection
总是选择第一帧来初始化网络并固定世界坐标系。每次添加新的关键帧时,我们都会锁定网络的副本,以表示该时间点的3D地图快照。后续帧将根据此副本进行检查,如果它们看到明显新的区域,则会被选中。
为了得到给定区域已经学习过场景的概率是多少,通过以下公式进行计算:
当学习率小于一定阈值,则将其添加到关键帧的集合中。
Active Sampling
Image Active Sampling
利用图像的规律性,在每次迭代中只渲染和优化一组非常稀疏的随机像素(每张图像200个)。渲染后,将图像拆分成 $8\times8$ 的网格,然后对损失高的小网格进行重采样。
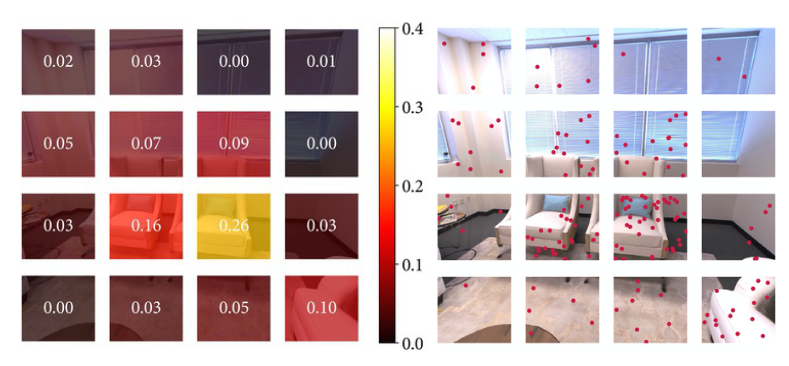
Keyframe Active Sampling
对于关键帧内的采样,使用的与图片采样相同的策略。
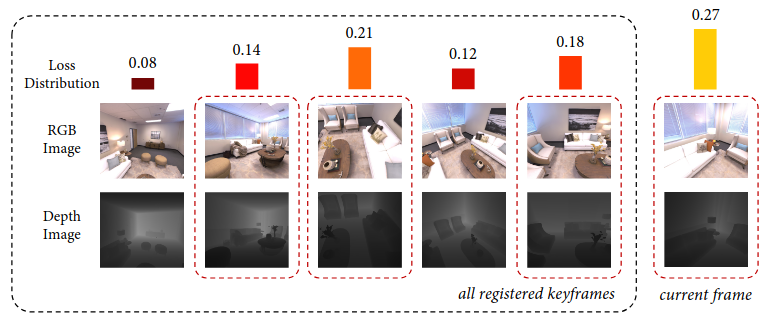
Bounded Keyframe Selection
在校正好的关键帧中选择损失较大的三帧,然后和当前帧,最后一个关键帧共5帧,一起进行联合优化。
4、NICE-SLAM: Neural Implicit Scalable Encoding for SLAM
摘要翻译
最近神经隐式表达已经在多个领域获得了令人鼓舞的结果,包括在SLAM领域富有成效的进步。然而,现有的方法会产生过度平滑的场景重建和难以放大到大场景的问题。这些限制主要是由于其简单的全连接网络,该结构没有整合观测的局部信息。本文中,我们提出了 NICE-SLAM,这是一个稠密的SLAM系统,它通过引入多层场景表达来结合多层局部信息。利用预训练的几何先验信息优化这种表示可以对室内大场景进行细致的重建。对比最近的神经隐式SLAM系统,我们的方法更具有可扩展性,高效性和鲁棒性。在五个具有挑战的数据集上的实验结果表明,NICE-SLAM在建图和追踪方面的质量都更具有竞争力。
方法介绍
- 问题定义
提出了 NICE-SLAM,这是一个稠密的SLAM系统,它通过引入多层场景表达来结合多层局部信息。利用预训练的几何先验信息优化这种表示可以对室内大场景进行细致的重建。
- Overview
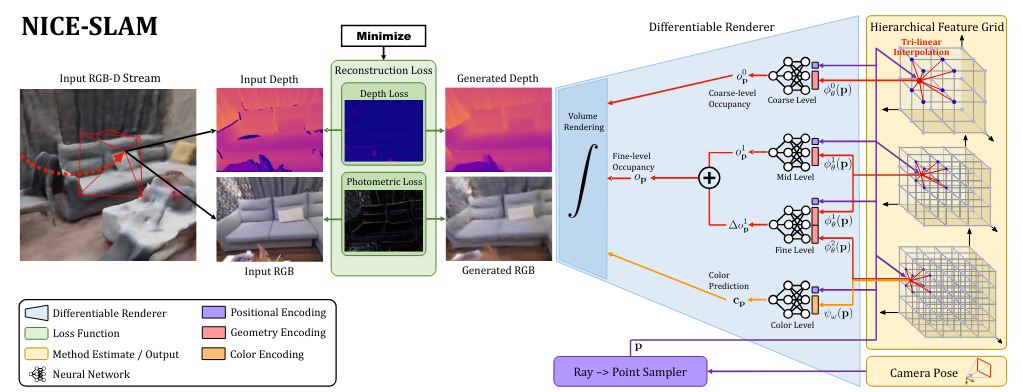
Hierarchical Scene Representation
Mid-&Fine-level Geometric Representation
其中首先通过优化中级特征网格来重建几何体,然后使用精细层进行细化。
细化层输入中层、细化层特征,输出与中层占据概率的偏差:
最终得到:
Coarse-level Geometric Representation
粗层主要捕获高层的几何特征,并由细化层和中层进行优化:
粗网格的目标是能够预测观察到的几何体(在中/精细级别中编码)之外的近似占用值,即使在仅部分观察到每个粗体素的情况下也是如此。
Pre-training Feature Decoders
采用 ConvONet 正常训练,但最后只采用其中的 MLP层作为渲染部分的 MLP 层网络参数。
Color Representation
体渲染公式
Network Design
除了粗糙层,其余层输入前采用高斯位置编码对位置 p 进行编码
Depth and Color Rendering
同 iMAP 相同,对每个级别的网络做相同的损失定义:
Mapping and Tracking
Mapping
几何和光度误差均为 L1 范数:
Camera Tracking
修改相机追踪的误差:
最终相机优化误差为:
Robustness to Dynamic Objects
为了使优化在跟踪过程中对动态对象更具鲁棒性,我们过滤了深度/颜色重渲染损失较大的像素。特别地,我们从优化中移除了所有在等式12的损失大于当前帧所有像素平均损失10倍的像素。
Keyframe Selection
区别于 iMAP,在优化场景几何体时,我们只包括与当前帧具有视觉重叠的关键帧。
5、Orbeez-SLAM: A Real-time Monocular Visual SLAM with ORB Features and NeRF-realized Mapping
摘要翻译
一种能够通过视觉信号执行复杂任务并与人类合作的空间型人工智能受到了极高的关注。为了实现这个目标,我们需要一个视觉SLAM,它无需预训练就可以适应新场景,并且可以为下游任务提供稠密的地图。由于系统内部组件的限制,之前的基于学习和非基于学习的视觉SLAM不能满足所有要求。在本文的工作中,我们开发了一个名为 Orbezz-SLAM的视觉SLAM系统,该系统能够成功地将隐式神经表达和视觉里程计进行融合,以实现我们的目标。此外,OrbeezSLAM可以与弹幕相机配合使用,因为它只需要输入RGB图像,这使得它可以广泛地适用于现实世界。结果表明,我们的SLAM比强基线指标快800倍,具有优异的渲染效果。
方法介绍
- 问题定义
设计一个视觉SLAM,它无需预训练就可以适应新场景,并且可以为下游任务提供稠密的地图。
- Pipeline
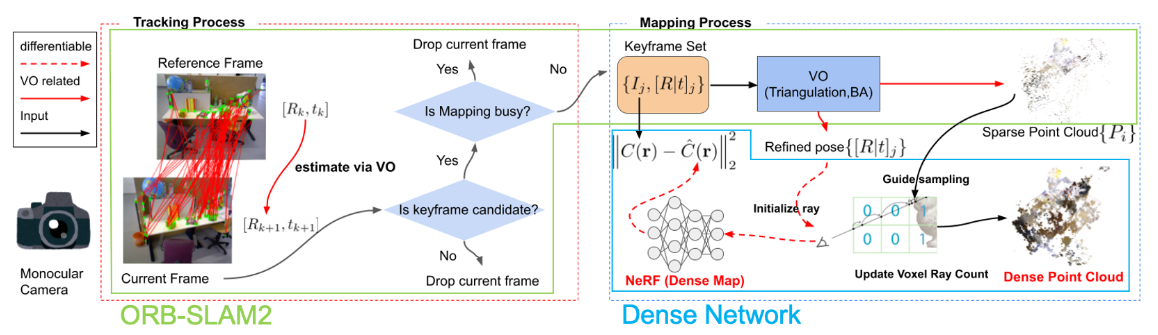
Optimization
位姿损失
重映射误差优化和BA:
光度损失
Ray-casting triangulation
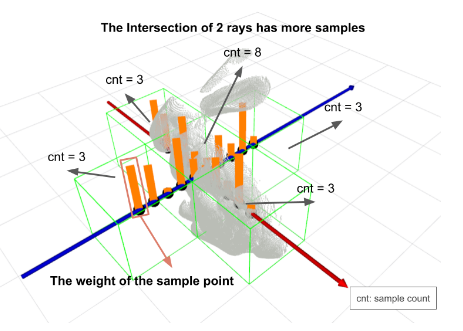
存储每个体素的采样次数。经常阻挡投射光线的体素更有可能是曲面;对于噪声抑制,我们只对位于射线扫描频率足够高的体素内的点进行三角测量。
6、Co-SLAM: Joint Coordinate and Sparse Parametric Encodings for Neural Real-Time SLAM
摘要翻译
我们提出了Co-SLAM,一种基于混合表示的神经RGB-D SLAM系统,它可以实时地执行鲁棒的相机跟踪和高保真的表面重建。Co-SLAM 采用多分辨率hash网格表示场景,以利用它的高收敛速度和表示高频局部特征的能力。此外,Co-SLAM结合了 one-blob 编码以促进未观测区域的表面一致性和完整性。通过两种最佳的领域,这种联合参数坐标编码实现了实时和鲁棒的表现性能:快速收敛性和空洞填充能力。此外,我们的射线采样策略允许Co-SLAM在所有关键帧上去执行全局BA,而不是像其他竞争的神经SLAM方法那样需要选择关键帧来维持少量激活的关键帧。实验结果表明,Co-SLAM以10-17Hz的频率运行,并实现了最先进的场景重建结果,以及在各种数据集和基准测试中表现出具有竞争力的追踪性能。
方法介绍
问题定义
设计一种混合表示的神经RGB-D SLAM系统,可以实时地执行鲁棒的相机跟踪和高保真的表面重建。区别于其他方法,Co-SLAM可以在所有关键帧上执行全局BA。
Pipeline
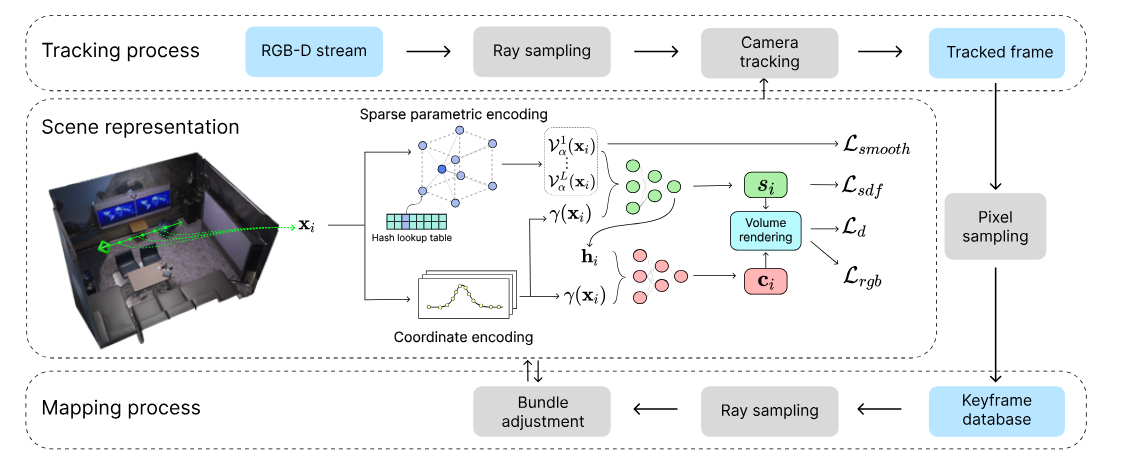
Joint Coordinate and Parametric Encoding
位置编码有助于保持一致性和光滑性先验,但收敛慢和产生遗忘问题;参数编码能提高效率但缺少空洞填补和光滑性。
几何编码得到特征向量和 SDF 值:
颜色编码得到对颜色的预测:
Depth and Color Rendering
颜色和深度通过体渲染公式得到:
权重值通过 SDF 转换函数得到,区别于 NeuS 中的权重转换函数,采用简单的 bell-shaped 模型计算:
Depth-guided Sampling:作者发现重要性采样没有显著提升系统的同时反而降低了追踪和建图的速率。所以除了均匀采样之外,还对有效的深度测量点附近做正负 ds 的均匀采样。
Tracking and Bundle Adjustment
Objective Functions
各个损失函数定义如下:
Camera Tracking
相机初始化采用匀速模型假设:
Bundle Adjustment
构建一个像素集合,储存每个关键帧约5%的像素,最后对整个像素集合的所有像素进行全局优化。
7、GO-SLAM: Global Optimization for Consistent 3D Instant Reconstruction
摘要翻译
最近,神经隐式表达在稠密SLAM领域取得了令人信服的结果,但是仍受限于相机追踪的累计误差和在重建过程中的扭曲变形。我们带有目的地提出GO-SLAM,一种基于深度学习的稠密视觉SLAM框架,用于实时地全局位姿优化和三维重建。鲁棒的位姿估计是其核心,由有效的闭环以及在线全局BA所支持,通过利用输入帧完整的历史的学习全局几何来优化每一帧。同时,我们动态更新隐式和连续曲面表达,以确保三维重建的全局一致性。在各种合成的和真实世界的数据集上的结果表明,GO-SLAM在跟踪鲁棒性和重建精度方面要优于其他SOTA方法。此外,GO-SLAM是通用的,可以输入单目、双目和RGB-D进行运行。
方法介绍
问题定义
我们带有目的地提出GO-SLAM,一种基于深度学习的稠密视觉SLAM框架,用于实时地全局位姿优化和三维重建。鲁棒的位姿估计是其核心,由有效的闭环以及在线全局BA所支持,通过利用输入帧完整的历史的学习全局几何来优化每一帧。
Overview
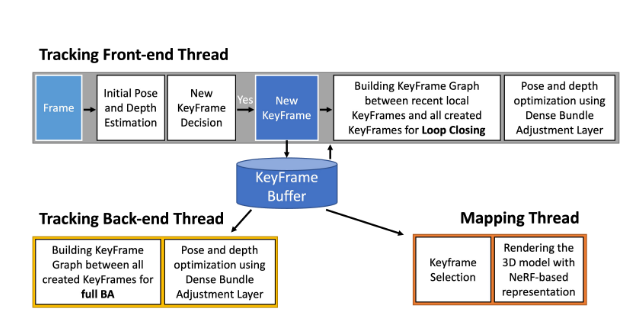
Tracking with Global Optimization
GO-SLAM 整个前端和后端线程均参照 DROID-SLAM 的结构,相对的是加入了新的回环检测和全局BA优化。
下文主要对新增的这两个模块做解释。
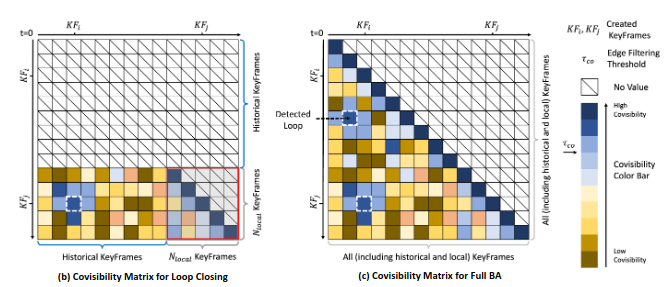
Loop Closing & Full BA
GO-SLAM 的回环检测和BA是基于关键帧的图优化:
- 选择最近的 N 个局部关键帧之间的高可视性连接;
- 从局部关键帧和局部窗口外的历史帧重检测回环。
为了提高计算效率,对建立优化边的两两关键帧进行领域抑制,具体而言就是限制每个关键帧可以构建优化边的数量不能超过某一个阈值。
从共视矩阵的未探索部分按共视程度降序采样,连续检测三个回环候选帧,如果平均流均低于阈值,则认为检测到了回环,然后进行优化。
Instant Mapping
渲染部分主要参考了 NeuS 模型,具体函数如下:
输入 hash 编码特征和原位置信息得到 SDF 值和几何特征:
输入 SDF 值和 SDF 梯度信息以及位置信息得到颜色的预测值:
体渲染:
各个损失函数如下:
正则项:
深度损失:
对不同 SDF 采取不同的损失策略:
最终损失函数如下: