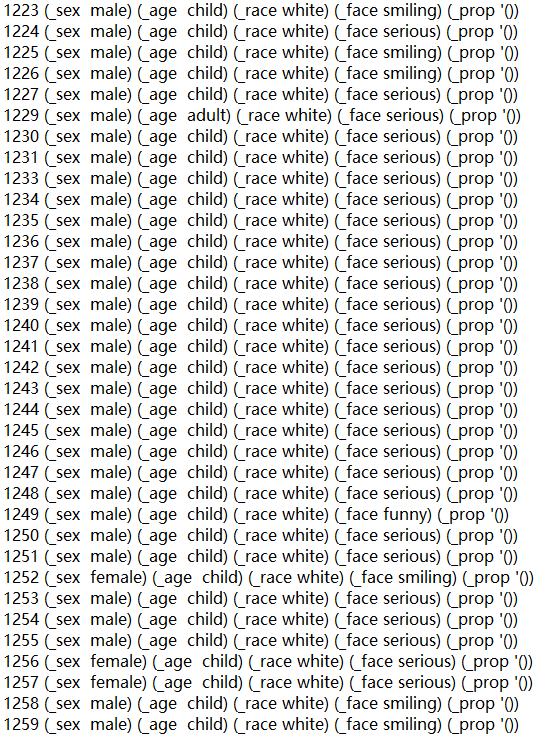
withopen(label_dir + '/faceDR', encoding='utf-8') as dr_label: facedr_list = [[buf.strip(')') for buf in line.strip().split(' (_')] for line in dr_label.readlines()] withopen(label_dir + '/faceDS', encoding='utf-8') as ds_label: faceds_list = [[buf.strip(')') for buf in line.strip().split(' (_')] for line in ds_label.readlines()] # 将 id号与人种组合
facedr = [] faceds = []
for line in facedr_list: race = line[3].strip().split(' ')[1] temp = [line[0], race] facedr.append(temp) print(facedr[:10])
for line in faceds_list: race = line[3].strip().split(' ')[1] temp = [line[0], race] faceds.append(temp) # 将数据转为npy格式
np.save('data.npy', facedr) data = np.load('data.npy')
基本思想是,每个样本的文件名即其 id,我们已经有了 ( id + 人种 )的数据,那么遍历所有的文件,若文件名中 id 与(id + 人种)的 id为同一个, 即将该人种信息标注于样本文件名中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
for fname in os.listdir(os.path.join('facedata', 'train')): ifnot fname.endswith('.png'): continue idt, _ = fname.split('.') filepath = os.path.join('facedata', 'train', fname) idt_num = int(idt) for label in train_label: if idt == label[0]: os.rename(filepath, filepath.replace('.', '.' + label[1] + '.') )
for fname in os.listdir(os.path.join('facedata', 'test')): ifnot fname.endswith('.png'): continue idt, _ = fname.split('.') filepath = os.path.join('facedata', 'test', fname) idt_num = int(idt) for label in test_label: if idt == label[0]: os.rename(filepath, filepath.replace('.', '.' + label[1] + '.') )
最后查看一下训练集与测试集中的样本分布
1 2 3 4 5 6 7 8 9 10 11
facedr_cnt = {} faceds_cnt = {}
for value in train_label: facedr_cnt[value[1]] = facedr_cnt.get(value[1], 0) + 1 for value in test_label: faceds_cnt[value[1]] = faceds_cnt.get(value[1], 0) + 1 print(facedr_cnt) print(faceds_cnt)