前言
最近接触了自动驾驶方向的一个子任务——Lane Detection,即车道线检测,查阅相关的文献,着手复现《Ultra Fast Structure-aware Deep Lane Detection》这篇文章的模型实验,在此对实验复现以及论文内容做简要总结记录。
论文:Ultra Fast Structure-aware Deep Lane Detection
代码:code地址
实验复现
前期准备
主要是深度学习环境的搭建,具体版本及搭建教程参考笔者这篇文章Ubuntu18.04下pytorch深度学习环境搭建
其中CUDA版本可以与作者不同。
环境部署
这里直接跟着作者的安装教程即可 INSTALL
注意可视化部分需要安装作者的 requirements,在安装文档里作者有相应提示
下载数据集
直接去作者安装教程里的超链接即可,若网速受限则参考下一部分笔者推荐的文档里的百度云
数据集解压整理
这里笔者第一次跑模型不太懂,查了老半天资料数据集要怎么放,主要参考这篇文档:车道线检测论文Ultra-Fast-Lane-Detection-master代码复现过程
里面有数据集的百度云链接
这里有个地方需要注意:笔者一开始看训练数据和测试数据有相同的文件夹,例如两者都有“0601”这个文件夹,笔者以为内容是一样的,所以就没有把测试集的数据合并一起,导致在最后跑测试集的时候,找不到对应的数据(但不影响训练)。所以相同命名文件夹要合并在一起。
训练模型
剩下部分直接跟着作者的README文档做即可
可视化
跑作者的demo.py文件即可,具体参考作者README中Visualization
结果
这里笔者在第一次跑训练模型的时候对train.py文件不做任何修改,导致每训练一次都保存一次训练好的模型,最后跑到70多轮的时候内存爆了……
解决上述问题很好解决,在train.py文件中修改保存模型代码即可,以下是笔者所作修改:
1 | for epoch in range(resume_epoch, cfg.epoch): |
可视化训练过程
主要参考这篇教程:详解PyTorch项目使用TensorboardX进行训练可视化
但笔者没有配置任何东西……(不太懂,不知道是不是作者已经配置好了什么)
直接安装
1 | pip install tensorboardX |
执行
1 | tensorboard --logdir log_path --bind_all |
论文学习
摘要
区别于传统的语义分割方法去做检测,作者采用了row-based selection problem using global features的方法去做车道检测,最大的优势在于计算量少,速度快;同时能根据global feature解决无视觉信息(no-visual-clue)情况下预测车道线位置,同时能取得不错的精度。在其轻量模型Res-18情况下能达到300+帧每秒。
简要介绍
总体来说每张图片预定义Row anchors同时指定(w+1)维的cells,检测就建立在上图预定义的网格之中。
这里作者介绍了自己该模型的三大特点:
- 利用 global features 更好解决 no-visual-clue 的问题
- 区别传统语义分割方法检测
- 计算少,速度快
方法(损失函数设计)
各变量说明
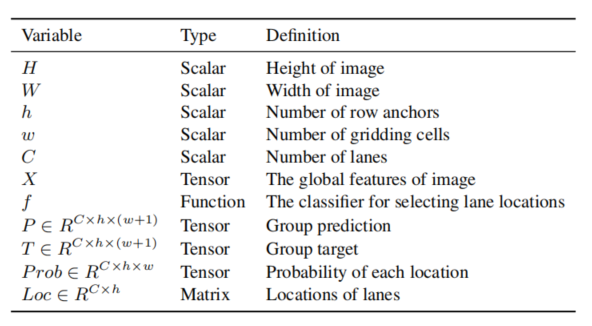
定位损失
基于此,本文该模型计算得到简化,在模型上体现为:
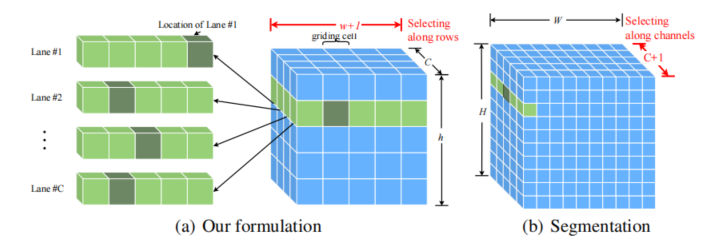
区别在于传统语义方法是整张图片,这里仅是预定义下的grid大小,同时 C仅取决于车道数量
这里作者重复强调(w+1)中多出来的一维是用来存放附加信息的,这里放到是该row anchor是否存在车道
车道结构损失
作者认为整体车道应该均为近似直线,哪怕是弯道,大部分视野内也是直线
相似损失(similarity loss)
形状损失(shape loss)
这里作者从一开始的argmax检测过渡到softmax检测有两点原因:
- softmax可微
- softmax可获得更多的连续信息
后续作者也有做两者的对比实验,结果softmax略胜一筹
最终得到
这里有一部分笔者觉得很妙,使用二阶微分做车道形状约束。如此,若为直线,则二阶的系数为零,这也是存在最多的情况,这样就不用设定专门的参数去学习一阶微分的分布。
总体结构损失
其中$L_{seg}$为分割损失(segmentation loss),为交叉熵损失(cross entropy)
网络搭建
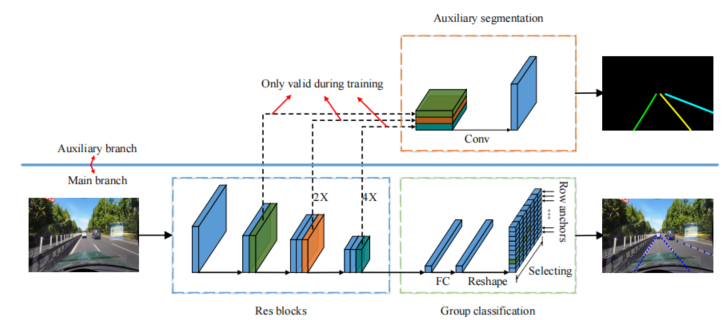
训练模式下使用辅助分支(auxiliary branch),测试过程去除该分支
实验及结果
数据集

这里作者对数据集进行了强化处理,通过图片操作延伸了部分车道以便使模型更具普遍性

消融实验
cell数量
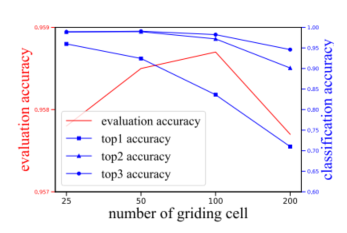
分类算法与回归算法

结构损失函数
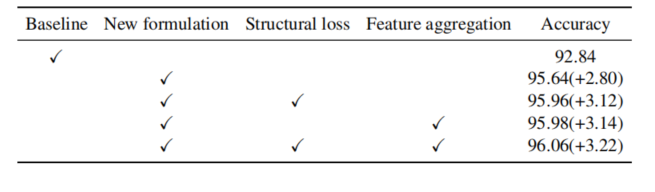
这里使用分类方法有助于损失函数的平滑
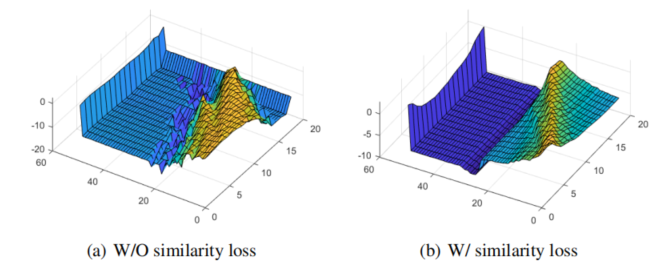
对比结果
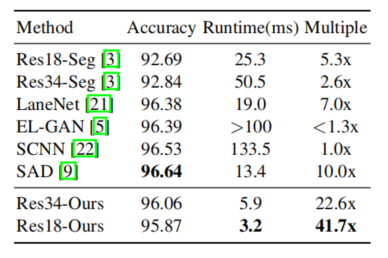
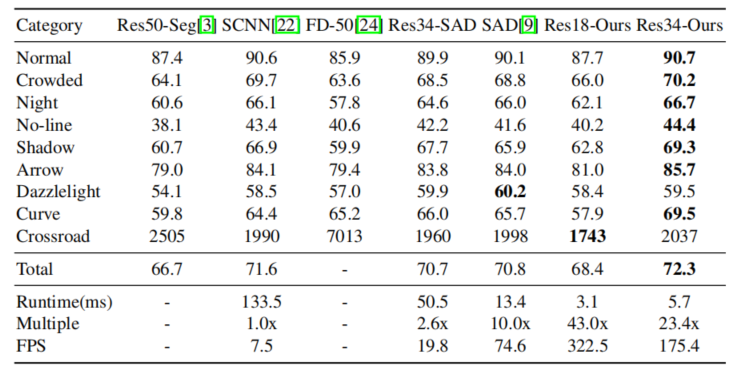
几个待解决的疑问
- global feature 本质是什么?
- 为什么row-based 有更好的感受野(receptive field)?
- which is caused by low-level pixel wise modeling and high-level long line structure of lane, can be bridged.这句的联系是什么?
- 这里为何相乘后叠加
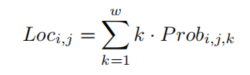
- 一阶微分为什么比二阶微分约束力强?
top1 top2 top3的概念不是很懂?
为什么一阶不用专门设计额外参数去学习?